Revolutionary SELD Tech Boosts Audio Detection in Surveillance, Driving, and Smart Homes
August 19, 2024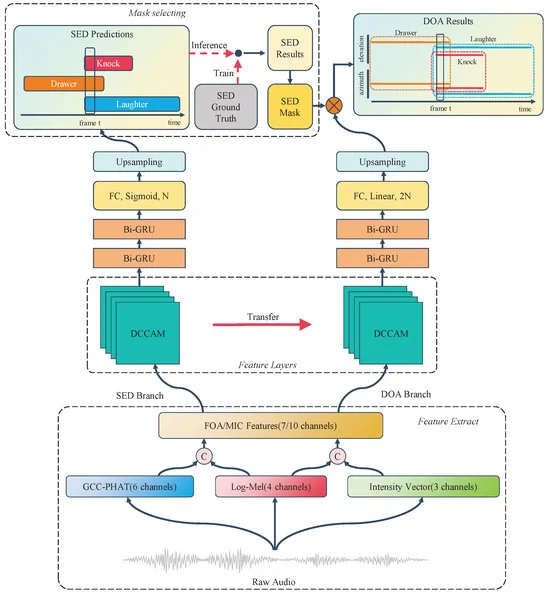
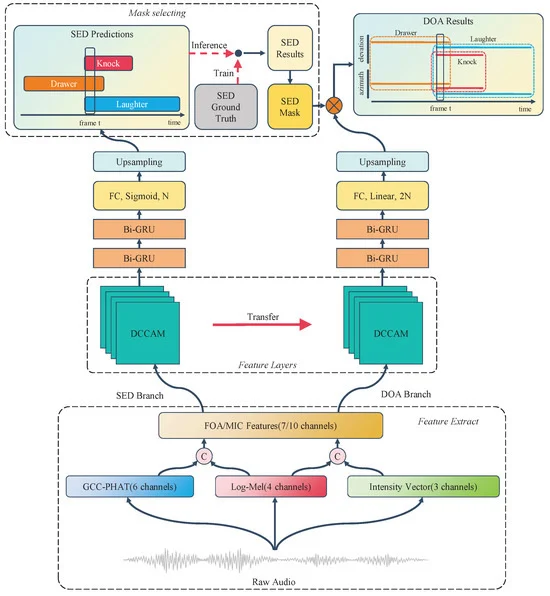
The Sound Event Localization and Detection (SELD) technology integrates Sound Event Detection (SED) and Semi-supervised Sound Localization (SSL) to identify sound events and their spatial locations, making it applicable in fields such as surveillance, automated driving, wildlife monitoring, and smart homes.
Recent advancements in deep learning, particularly through the use of Convolutional Recurrent Neural Networks (CRNN), have significantly enhanced feature extraction for both SED and Direction of Arrival (DOA) tasks.
These advancements aim to improve the detection performance of audio signal classification systems, addressing the limitations of existing methods while ensuring efficiency.
To further enhance temporal feature modeling, a two-layer Bi-GRU has been integrated, along with frequency and time mask data augmentation techniques to bolster model robustness.
The SELD-oriented Temporal Dual Convolutional Attention Module (TDCAM) employs a joint loss function to optimize performance in both SED and DOA tasks.
Innovations such as the Dual Branch Attention Module (DBAM) and Coordinate Attention mechanisms have been introduced to improve feature detection in overlapping sound events.
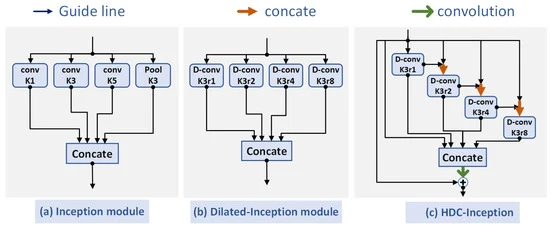
The manuscript also presents the HDC-Inception module, which combines Inception's parallel paths with Hybrid Dilated Convolution (HDC) to effectively capture varying temporal dependencies and enhance the network's ability to model audio signals of different durations.
While initial SED detection methods relied on Gaussian mixture models and Hidden Markov Models, recent advancements in deep learning have led to semi-supervised learning techniques that address the scarcity of labeled datasets.
Despite these advancements, challenges persist in capturing long short-term dependencies and managing class imbalance in datasets, particularly when background noise overwhelms actual signal events.
Experimental results utilizing the TAU Spatial Sound Events 2019 dataset, which includes audio files recorded in various formats, validate the effectiveness of the proposed models.
The proposed system incorporates a Dual Convolutional Attention Module (DCAM) that captures local features, enhancing SELD accuracy in complex environments.
Overall, audio signal detection and classification play a crucial role in identifying signal types in recordings and estimating onset and offset times, with applications spanning audio surveillance and environmental sound recognition.
Summary based on 2 sources